



1. 获取小说-笔趣阁
只用于技术研究,不允许非法用途
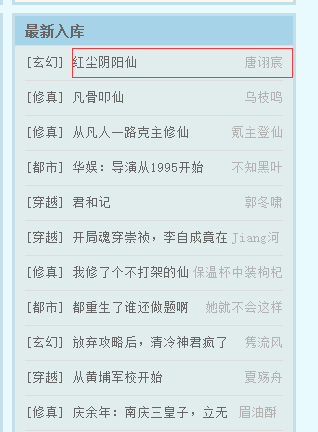
获取列表
代码
# 地址: https://www.um399.com/
# 获取笔趣阁中最新入库内容
import requests
from lxml import etree
url = "https://www.um399.com/"
## 添加请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf8'
#获取响应页内容
data = response.content.decode()
#实例化匹配对象
tree = etree.HTML(data)
#获取最新入库列表
li_list = tree.xpath("//div[@class='border3-1 popular']/div[@class='list-out']")
count=0
for li in li_list:
count = count + 1
# 获取图书名称
# text() 获取文本节点
# 获取书名
book_name = li.xpath('./span/a/text()')[0]
# 获取作者
author = li.xpath('./span/text()')[1]
print("书名:{},作者:{}".format(book_name,author))
print("总数:{}".format(count))
评论区