



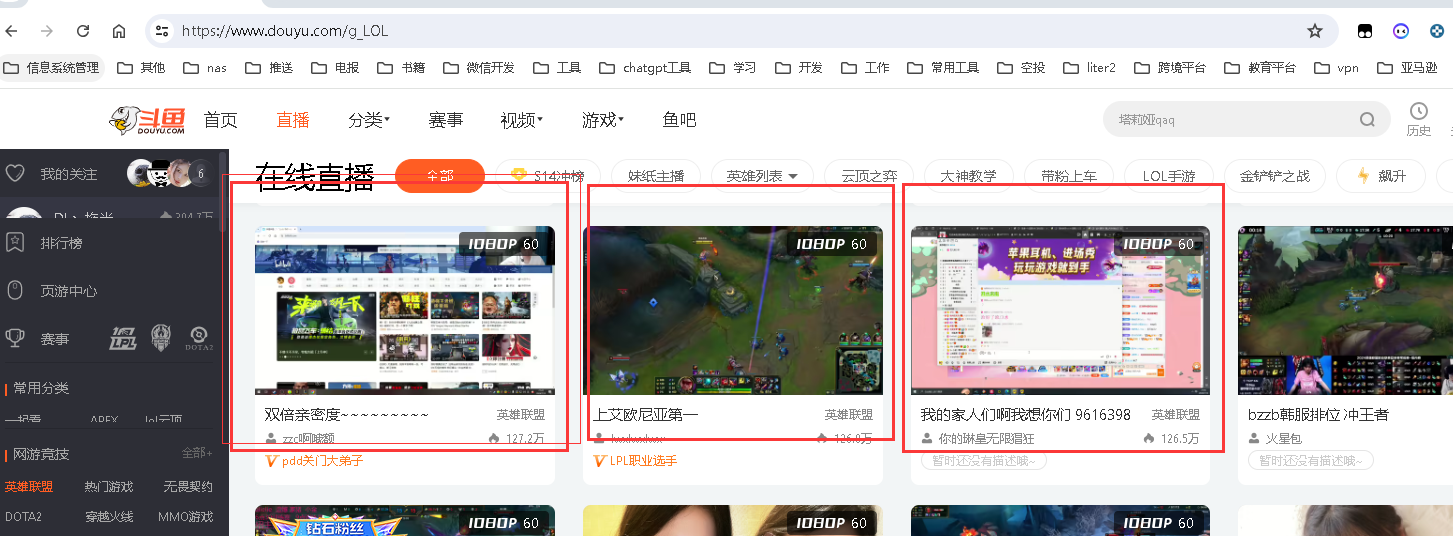
4. 斗鱼首页图片
只用于技术研究,不允许非法用途
截图
源码
# 地址: https://www.douyu.com/g_LOL
# 获取抖音某频道照片
# 开发时间 2024/07/12
import requests
import re
from lxml import etree,html
def get_html():
url = 'https://www.douyu.com/g_LOL'
## 添加请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
resp = requests.get(url=url,headers=headers)
tree = etree.HTML(resp.content.decode())
return tree.xpath("//div[@class='layout-Module-container layout-Cover ListContent']/ul[@class='layout-Cover-list']/li")
def parse(node_list):
lst = []
count = 0
for node in node_list:
count = count+1
str = html.tostring(node, pretty_print=True, encoding='unicode')
lst.append((count,re.findall('<img loading="lazy" src="(.*?)"', str)[0]))
return lst
if __name__ == '__main__':
lst = parse(get_html())
print(lst)

评论区